

前言
为了做Ins资源的备份,在网上找了半天,终于在Github上找到了instaloader,可以把ins上的一整个帖子爬下来,包括视频、文字
配置
获取session
在开始爬取之前,需要获取一下ins的session,这样可以下载最高质量的图片,由于官方给的用密码登录ins不太好使,所以选择从FireFox中获取session
首先需要在FireFox中登录ins账号,然后运行下面这段代码
from argparse import ArgumentParser
from glob import glob
from os.path import expanduser
from platform import system
from sqlite3 import OperationalError, connect
try:
from instaloader import ConnectionException, Instaloader
except ModuleNotFoundError:
raise SystemExit("Instaloader not found.\n pip install [--user] instaloader")
def get_cookiefile():
default_cookiefile = {
"Windows": "~/AppData/Roaming/Mozilla/Firefox/Profiles/*/cookies.sqlite",
"Darwin": "~/Library/Application Support/Firefox/Profiles/*/cookies.sqlite",
}.get(system(), "~/.mozilla/firefox/*/cookies.sqlite")
cookiefiles = glob(expanduser(default_cookiefile))
if not cookiefiles:
raise SystemExit("No Firefox cookies.sqlite file found. Use -c COOKIEFILE.")
return cookiefiles[0]
def import_session(cookiefile, sessionfile):
print("Using cookies from {}.".format(cookiefile))
conn = connect(f"file:{cookiefile}?immutable=1", uri=True)
try:
cookie_data = conn.execute(
"SELECT name, value FROM moz_cookies WHERE baseDomain='instagram.com'"
)
except OperationalError:
cookie_data = conn.execute(
"SELECT name, value FROM moz_cookies WHERE host LIKE '%instagram.com'"
)
instaloader = Instaloader(max_connection_attempts=1)
instaloader.context._session.cookies.update(cookie_data)
username = instaloader.test_login()
if not username:
raise SystemExit("Not logged in. Are you logged in successfully in Firefox?")
print("Imported session cookie for {}.".format(username))
instaloader.context.username = username
instaloader.save_session_to_file(sessionfile)
if __name__ == "__main__":
p = ArgumentParser()
p.add_argument("-c", "--cookiefile")
p.add_argument("-f", "--sessionfile")
args = p.parse_args()
try:
import_session(args.cookiefile or get_cookiefile(), args.sessionfile)
except (ConnectionException, OperationalError) as e:
raise SystemExit("Cookie import failed: {}".format(e))
然后就可以愉快地爬取了
使用命令行开始爬取,按照官方给的指示和自己的需求填字段就行
instaloader [--comments] [--geotags]
[--stories] [--highlights] [--tagged] [--igtv]
[--login YOUR-USERNAME] [--fast-update]
profile | "#hashtag" | %location_id |
:stories | :feed | :saved
举个例子,按照我需要爬取新账户和更新已爬取账户的资源的需求,我一般都是这样写
.\instaloader.exe --login [your_file_name] --latest-stamps -- [profile_name]
处理数据
在爬取完账户后,在根目录中应该已经出现了一个以账户名命名的文件夹,文件夹里是这个账户的所有资源
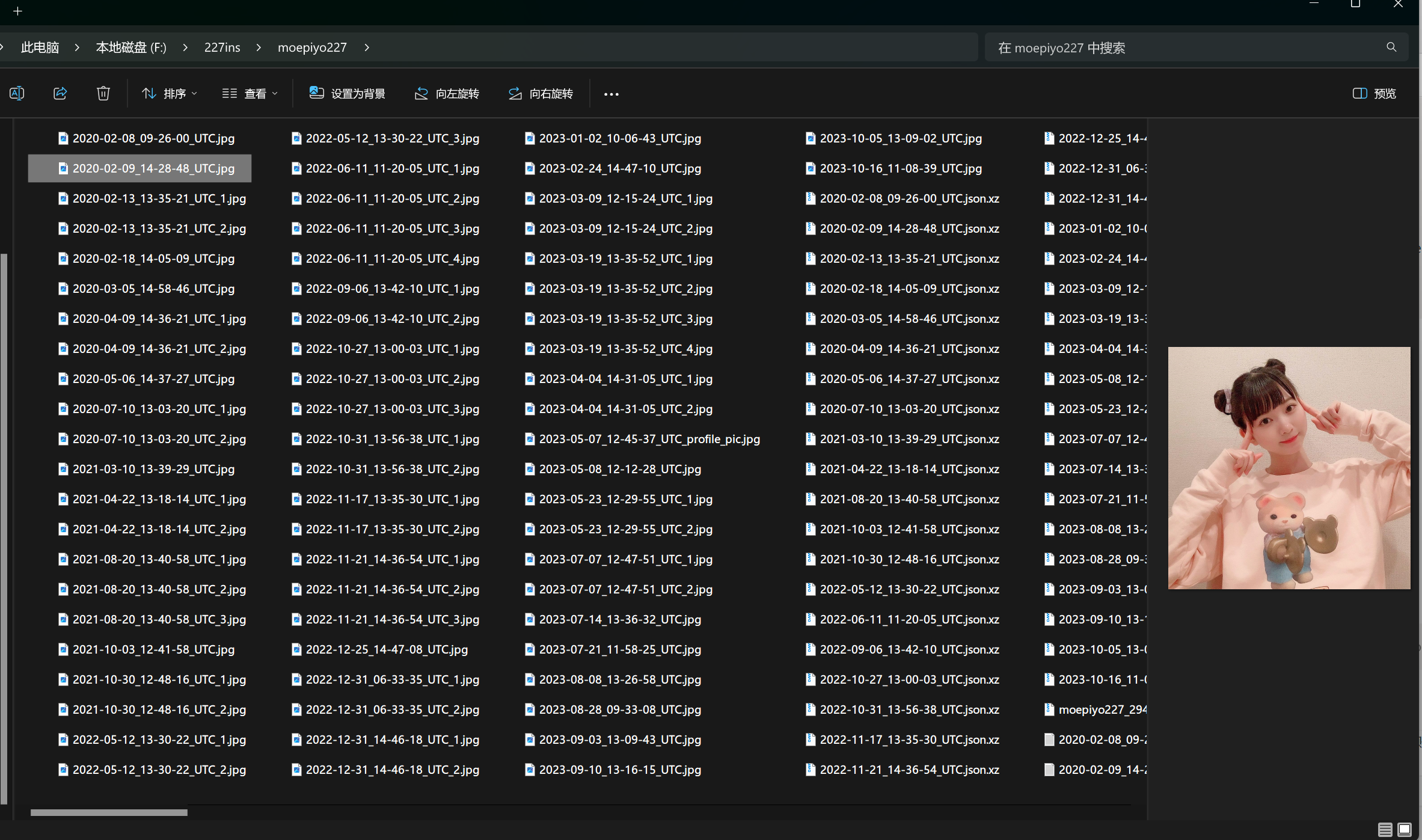
在这其中,txt文档储存的是这一条帖子的文字,当一个帖子有多个图片时候,会以UTC_1,UTC_2等方式来区别,这极大的方便了我进行相册配置文件的生成
文件夹映射
因为我习惯用成员的名字来指代,所以需要写一个函数来进行名字与账户名的映射
def cname(i):
if i == "kanae":
return "__shiro227"
if i == "sally":
return "sallyamaki"
if i == "moe":
return "moepiyo227"
if i == "uta":
return "kawase_uta"
if i == "mao":
return "asaoka_mao__"
if i == "rino":
return "cure_rinochi"
if i == "satsuki":
return "shiina_satsuki227"
获取路径
因为在根目录下有许多不同账户的目录,所以需要在每一轮循环确定这一次遍历的文件夹的路径
member=["kanae","sally","moe","uta","mao","rino","satsuki"]
for i in member:
path = cname(i)
rp=Path(Path.cwd(),path)
获取文件名
首先需要进行文件名分割,我们需要获取的是所有txt文件的名称,并将其储存在一个列表中,以便我们后续取用
使用splitext()将文件名与后缀名分割,并判断文件类型是否为txt,若为txt,则把文件名存入列表中
def checkfile(f):
global filename
filename=[]
for i in f:
if os.path.splitext(i)[1] == '.txt':
filename.insert(0,os.path.splitext(i)[0]) #保存文件名
遍历文件夹
现在我们已经写好了获取文件名的函数,同时也知道了文件夹的路径,我们需要做的是用checkfile()来遍历所有文件名,获取所有固定的前缀名
file_list = os.listdir(path)
checkfile(file_list)
写入文字内容
文字内容应该接在二级条目- content:之后,所以,在开头也不能出现一些特殊字符,例如@,:,-,在转录文本内容时应该同时去除
with open(Path(rp,i+".txt"),"r" ,encoding="utf-8") as t:
result = ''
for line in t:
if line[0]=="@":
line=line.replace("@","")
if line[0]=="*":
line=line.replace("*","")
if line[0]=="-":
line=line.replace("-","——")
line=line.replace(":",":")
因为一条文本经常会被换很多行,所以需要整合在一行内,需要利用strip()去除首尾多余的空格和换行
result += line.strip()
图片处理
判断图片个数
因为存在多图的帖子,所以需要再写入之前进行判断帖子的图片个数
因为只有一张图的帖子的图片后缀名之前的名称是和我们前一步提取出来的名称相同的,所以我们只需要判断前缀名相同的图片是否存在即可判断是否存在多图
for i in filename:
if Path(rp,i+".jpg").exists():
写入链接
对于单图的情况,十分直接,只需要直接写入就行,需要注意不同级别条目的缩进
f.write(" - https://files.227wiki.eu.org/d/Backup/Instagram/"+path+"/"+i+".jpg\n")
path代表图片的文件夹名称
而对于多图情况,我们需要在UTC后面加上编号,同时确保不会写多
因为一般最多不会超过九张,所以进行从1到9的循环,判断文件是否存在,若存在则直接写入
f.write(" - content: "+result+"\n image:\n")
for j in range(1,10):
fn=i+"_"+str(j)+".jpg"
if Path(rp,fn).exists():
f.write(" - https://files.227wiki.eu.org/d/Backup/Instagram/"+path+"/"+fn+"\n")
rp代表文件夹本地路径
写入元数据
写入帖子元数据
因为在文件名中直接包含了发帖时间,所以我们只需要从文件名中截取部分来作为日期即可,同时,还要注明来源是Instagram
f.write(" date: "+i[0:10]+"\n")
f.write(" from: Instagram\n")
所以,整个完整的函数的代码是这样的
def write_content():
for i in filename:
if Path(rp,i+".jpg").exists():
with open(Path(Path.cwd(),"album.yml"),"a",encoding='utf-8') as f:
with open(Path(rp,i+".txt"),"r" ,encoding="utf-8") as t:
result = ''
for line in t:
if line[0]=="@":
line=line.replace("@","")
if line[0]=="*":
line=line.replace("*","")
if line[0]=="-":
line=line.replace("-","——")
line=line.replace(":",":")
result += line.strip()
f.write(" - content: "+result+"\n image:\n")
f.write(" - https://files.227wiki.eu.org/d/Backup/Instagram/"+path+"/"+i+".jpg\n")
f.write(" date: "+i[0:10]+"\n")
f.write(" from: Instagram\n")
else:
with open(Path(Path.cwd(),"album.yml"),"a",encoding='utf-8') as f:
with open(Path(rp,i+".txt"),"r" ,encoding="utf-8") as t:
result = ''
for line in t:
if line[0]=="@":
line=line.replace("@","")
if line[0]=="*":
line=line.replace("*","")
if line[0]=="-":
line=line.replace("-","——")
line=line.replace(":",":")
result += line.strip()
f.write(" - content: "+result+"\n image:\n")
for j in range(1,10):
fn=i+"_"+str(j)+".jpg"
if Path(rp,fn).exists():
f.write(" - https://files.227wiki.eu.org/d/Backup/Instagram/"+path+"/"+fn+"\n")
f.write(" date: "+i[0:10]+"\n")
f.write(" from: Instagram\n")
设置个性元数据
因为每个人的相册封面和头图都是不同的,所以需要专门建立一些列表来存储
kanae_pic=["https://files.227wiki.eu.org/d/Backup/Instagram/__shiro227/2022-07-19_14-22-01_UTC_1.jpg","https://files.227wiki.eu.org/d/Backup/Instagram/__shiro227/2021-10-23_12-00-35_UTC.jpg"]
sally_pic=["https://files.227wiki.eu.org/d/Backup/Instagram/sallyamaki/2023-05-29_04-01-46_UTC.jpg","https://files.227wiki.eu.org/d/Backup/Instagram/sallyamaki/2023-03-22_07-23-26_UTC_1.jpg"]
moe_pic=["https://files.227wiki.eu.org/d/Backup/Instagram/moepiyo227/2023-02-24_14-47-10_UTC.jpg","https://files.227wiki.eu.org/d/Backup/Instagram/moepiyo227/2023-07-14_13-36-32_UTC.jpg"]
uta_pic=["https://files.227wiki.eu.org/d/Backup/Instagram/kawase_uta/2022-03-07_07-16-26_UTC_3.jpg","https://files.227wiki.eu.org/d/Backup/Instagram/kawase_uta/2022-08-23_10-18-31_UTC_2.jpg"]
mao_pic=["https://files.227wiki.eu.org/d/Backup/Instagram/asaoka_mao__/2023-08-27_11-02-11_UTC_7.jpg","https://files.227wiki.eu.org/d/Backup/Instagram/asaoka_mao__/2023-10-31_08-47-24_UTC_4.jpg"]
rino_pic=["https://files.227wiki.eu.org/d/Backup/Instagram/cure_rinochi/2023-09-16_12-37-57_UTC_1.jpg","https://files.227wiki.eu.org/d/Backup/Instagram/cure_rinochi/2023-08-12_10-27-08_UTC_2.jpg"]
satsuki_pic=["https://files.227wiki.eu.org/d/Backup/Instagram/shiina_satsuki227/2023-11-11_15-08-28_UTC_1.jpg","https://files.227wiki.eu.org/d/Backup/Instagram/shiina_satsuki227/2023-04-13_04-40-16_UTC_1.jpg"]
再根据不同的成员返回不同的元数据
def head(i):
if i == "kanae":
return " cover: "+kanae_pic[0]+"\n top_background: "+kanae_pic[1]+"\n description: 白泽加奈惠\n"
if i == "sally":
return " cover: "+sally_pic[0]+"\n top_background: "+sally_pic[1]+"\n description: 天城莎莉\n"
if i == "moe":
return " cover: "+moe_pic[0]+"\n top_background: "+moe_pic[1]+"\n description: 凉花萌\n"
if i == "uta":
return " cover: "+uta_pic[0]+"\n top_background: "+uta_pic[1]+"\n description: 河瀬詩\n"
if i == "mao":
return " cover: "+mao_pic[0]+"\n top_background: "+mao_pic[1]+"\n description: 麻丘真央\n"
if i == "rino":
return " cover: "+rino_pic[0]+"\n top_background: "+rino_pic[1]+"\n description: 望月りの\n"
if i == "satsuki":
return " cover: "+satsuki_pic[0]+"\n top_background: "+satsuki_pic[1]+"\n description: 椎名桜月\n"
...
j.write(head(i))
写入固定元数据
最后就是要写入一些不需要变动的元数据
with open(Path(Path.cwd(),"album.yml"),"a",encoding='utf-8') as j:
if path == "__shiro227":
j.write("- path_name: /shiro227/\n")
else:
j.write("- path_name: /"+path+"/\n")
j.write(" type: 1\n")
j.write(" lazyload: true\n")
j.write(" btnLazyload: false\n")
j.write(" url: false\n")
j.write(" top_link: /ins\n")
j.write(" top_btn_text: 返回\n")
j.write(" class_name: Instagram\n")
j.write(" album_list:\n")
所以,整个写入元数据的部分应该是这样的
with open(Path(Path.cwd(),"album.yml"),"a",encoding='utf-8') as j:
if path == "__shiro227":
j.write("- path_name: /shiro227/\n")
else:
j.write("- path_name: /"+path+"/\n")
j.write(head(i))
j.write(" type: 1\n")
j.write(" lazyload: true\n")
j.write(" btnLazyload: false\n")
j.write(" url: false\n")
j.write(" top_link: /ins\n")
j.write(" top_btn_text: 返回\n")
j.write(" class_name: Instagram\n")
j.write(" album_list:\n")
write_content()
这一部分应该嵌套在成员名字的循环中
到这里基本上所有处理流程都结束了,这时候只需要打开根目录的album.yml,将里面的内容复制到相册的配置文件中就行了
完整代码
import os
from pathlib import *
filename=[]
outlist=[]
member=["kanae","sally","moe","uta","mao","rino","satsuki"]
kanae_pic=["https://files.227wiki.eu.org/d/Backup/Instagram/__shiro227/2022-07-19_14-22-01_UTC_1.jpg","https://files.227wiki.eu.org/d/Backup/Instagram/__shiro227/2021-10-23_12-00-35_UTC.jpg"]
sally_pic=["https://files.227wiki.eu.org/d/Backup/Instagram/sallyamaki/2023-05-29_04-01-46_UTC.jpg","https://files.227wiki.eu.org/d/Backup/Instagram/sallyamaki/2023-03-22_07-23-26_UTC_1.jpg"]
moe_pic=["https://files.227wiki.eu.org/d/Backup/Instagram/moepiyo227/2023-02-24_14-47-10_UTC.jpg","https://files.227wiki.eu.org/d/Backup/Instagram/moepiyo227/2023-07-14_13-36-32_UTC.jpg"]
uta_pic=["https://files.227wiki.eu.org/d/Backup/Instagram/kawase_uta/2022-03-07_07-16-26_UTC_3.jpg","https://files.227wiki.eu.org/d/Backup/Instagram/kawase_uta/2022-08-23_10-18-31_UTC_2.jpg"]
mao_pic=["https://files.227wiki.eu.org/d/Backup/Instagram/asaoka_mao__/2023-08-27_11-02-11_UTC_7.jpg","https://files.227wiki.eu.org/d/Backup/Instagram/asaoka_mao__/2023-10-31_08-47-24_UTC_4.jpg"]
rino_pic=["https://files.227wiki.eu.org/d/Backup/Instagram/cure_rinochi/2023-09-16_12-37-57_UTC_1.jpg","https://files.227wiki.eu.org/d/Backup/Instagram/cure_rinochi/2023-08-12_10-27-08_UTC_2.jpg"]
satsuki_pic=["https://files.227wiki.eu.org/d/Backup/Instagram/shiina_satsuki227/2023-11-11_15-08-28_UTC_1.jpg","https://files.227wiki.eu.org/d/Backup/Instagram/shiina_satsuki227/2023-04-13_04-40-16_UTC_1.jpg"]
def cname(i):
if i == "kanae":
return "__shiro227"
if i == "sally":
return "sallyamaki"
if i == "moe":
return "moepiyo227"
if i == "uta":
return "kawase_uta"
if i == "mao":
return "asaoka_mao__"
if i == "rino":
return "cure_rinochi"
if i == "satsuki":
return "shiina_satsuki227"
def head(i):
if i == "kanae":
return " cover: "+kanae_pic[0]+"\n top_background: "+kanae_pic[1]+"\n description: 白泽加奈惠\n"
if i == "sally":
return " cover: "+sally_pic[0]+"\n top_background: "+sally_pic[1]+"\n description: 天城莎莉\n"
if i == "moe":
return " cover: "+moe_pic[0]+"\n top_background: "+moe_pic[1]+"\n description: 凉花萌\n"
if i == "uta":
return " cover: "+uta_pic[0]+"\n top_background: "+uta_pic[1]+"\n description: 河瀬詩\n"
if i == "mao":
return " cover: "+mao_pic[0]+"\n top_background: "+mao_pic[1]+"\n description: 麻丘真央\n"
if i == "rino":
return " cover: "+rino_pic[0]+"\n top_background: "+rino_pic[1]+"\n description: 望月りの\n"
if i == "satsuki":
return " cover: "+satsuki_pic[0]+"\n top_background: "+satsuki_pic[1]+"\n description: 椎名桜月\n"
def checkfile(f):
global filename
filename=[]
for i in f:
if os.path.splitext(i)[1] == '.txt':
filename.insert(0,os.path.splitext(i)[0])
def write_content():
for i in filename:
if Path(rp,i+".jpg").exists():
with open(Path(Path.cwd(),"album.yml"),"a",encoding='utf-8') as f:
with open(Path(rp,i+".txt"),"r" ,encoding="utf-8") as t:
result = ''
for line in t:
if line[0]=="@":
line=line.replace("@","")
if line[0]=="*":
line=line.replace("*","")
if line[0]=="-":
line=line.replace("-","——")
line=line.replace(":",":")
result += line.strip()
f.write(" - content: "+result+"\n image:\n")
f.write(" - https://files.227wiki.eu.org/d/Backup/Instagram/"+path+"/"+i+".jpg\n")
f.write(" date: "+i[0:10]+"\n")
f.write(" from: Instagram\n")
else:
with open(Path(Path.cwd(),"album.yml"),"a",encoding='utf-8') as f:
with open(Path(rp,i+".txt"),"r" ,encoding="utf-8") as t:
result = ''
for line in t:
if line[0]=="@":
line=line.replace("@","")
if line[0]=="*":
line=line.replace("*","")
if line[0]=="-":
line=line.replace("-","——")
line=line.replace(":",":")
result += line.strip()
f.write(" - content: "+result+"\n image:\n")
for j in range(1,10):
fn=i+"_"+str(j)+".jpg"
if Path(rp,fn).exists():
f.write(" - https://files.227wiki.eu.org/d/Backup/Instagram/"+path+"/"+fn+"\n")
f.write(" date: "+i[0:10]+"\n")
f.write(" from: Instagram\n")
if __name__ == "__main__":
with open(Path(Path.cwd(),"album.yml"),"w",encoding='utf-8') as f:
f.seek(0)
f.write("")
for i in member:
path = cname(i)
rp=Path(Path.cwd(),path)
file_list = os.listdir(path)
checkfile(file_list)
with open(Path(Path.cwd(),"album.yml"),"a",encoding='utf-8') as j:
if path == "__shiro227":
j.write("- path_name: /shiro227/\n")
else:
j.write("- path_name: /"+path+"/\n")
j.write(head(i))
j.write(" type: 1\n")
j.write(" lazyload: true\n")
j.write(" btnLazyload: false\n")
j.write(" url: false\n")
j.write(" top_link: /ins\n")
j.write(" top_btn_text: 返回\n")
j.write(" class_name: Instagram\n")
j.write(" album_list:\n")
write_content()
实现效果
访问22/7 Blog查看

Comments NOTHING